
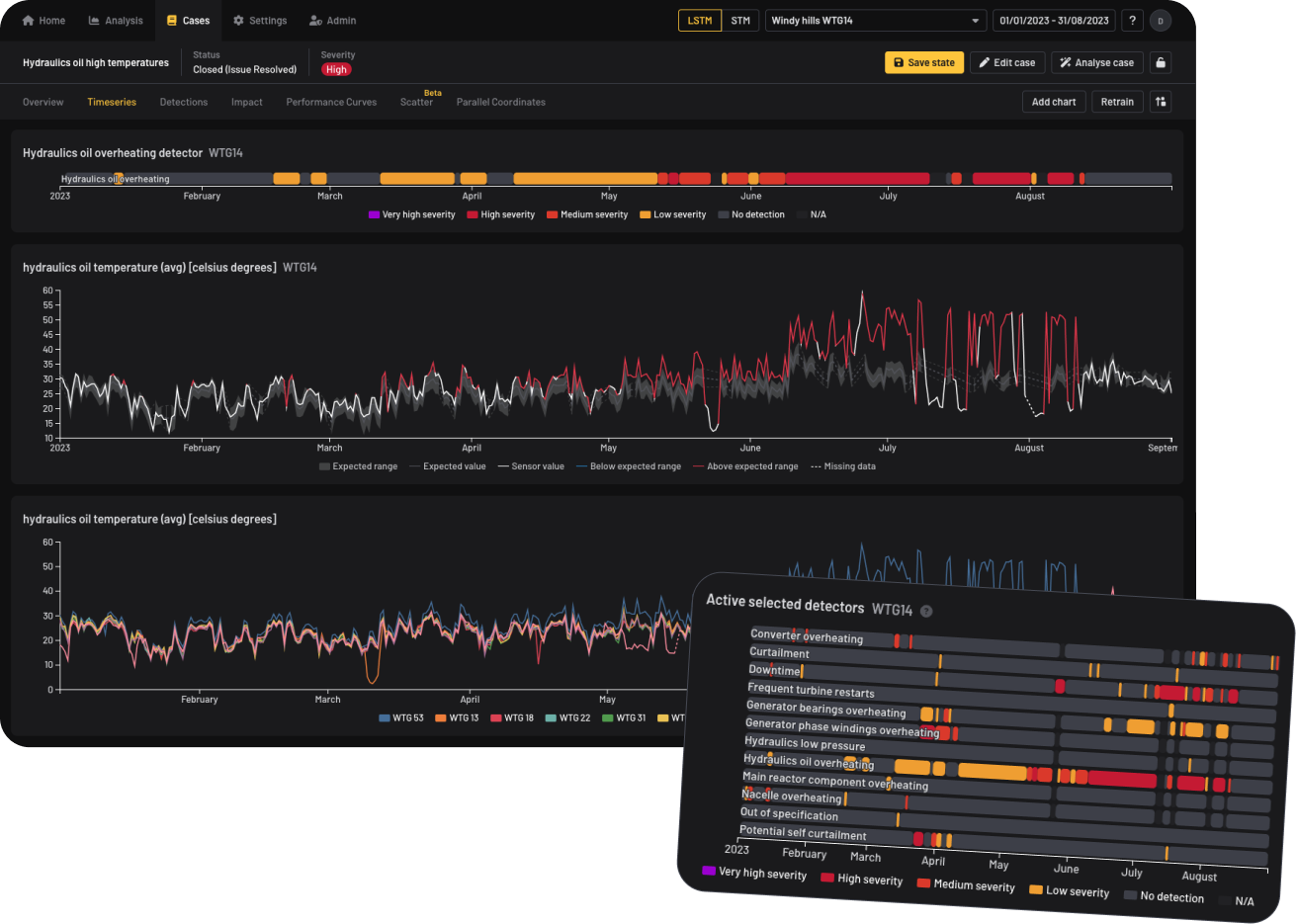

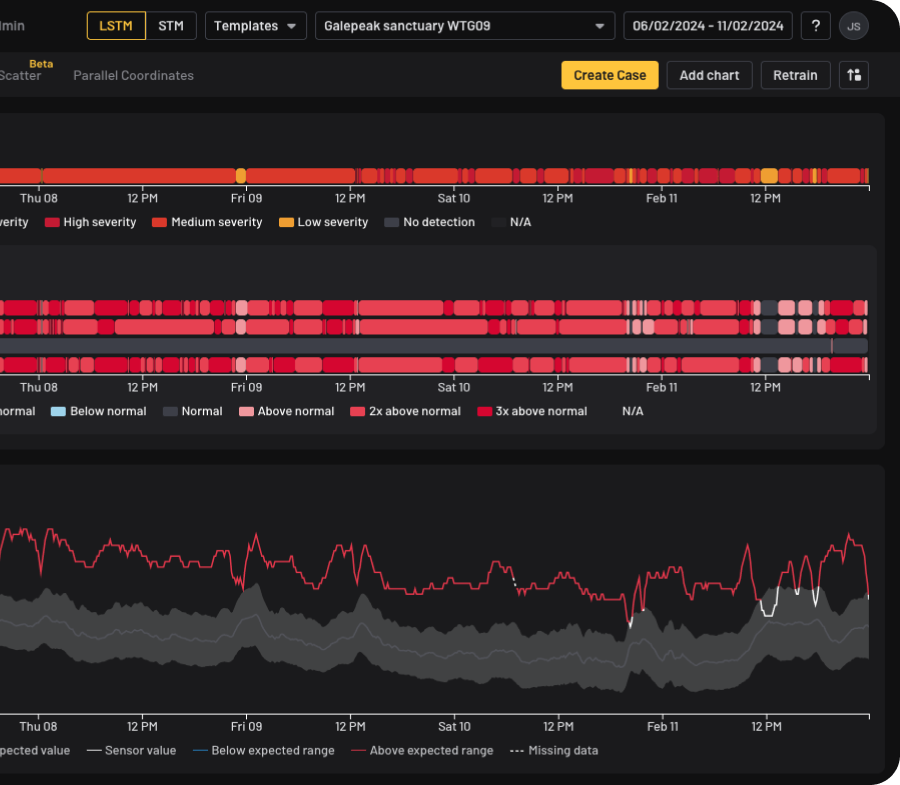

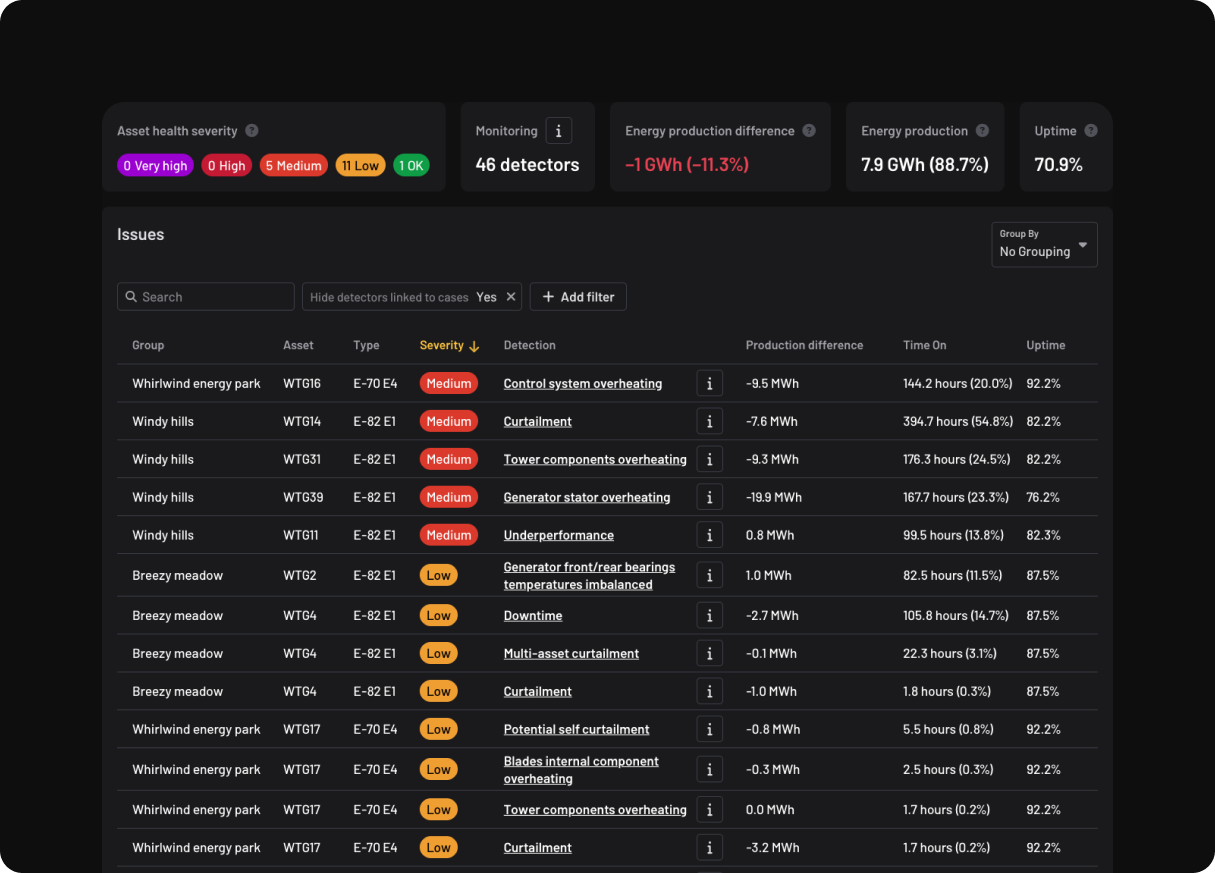
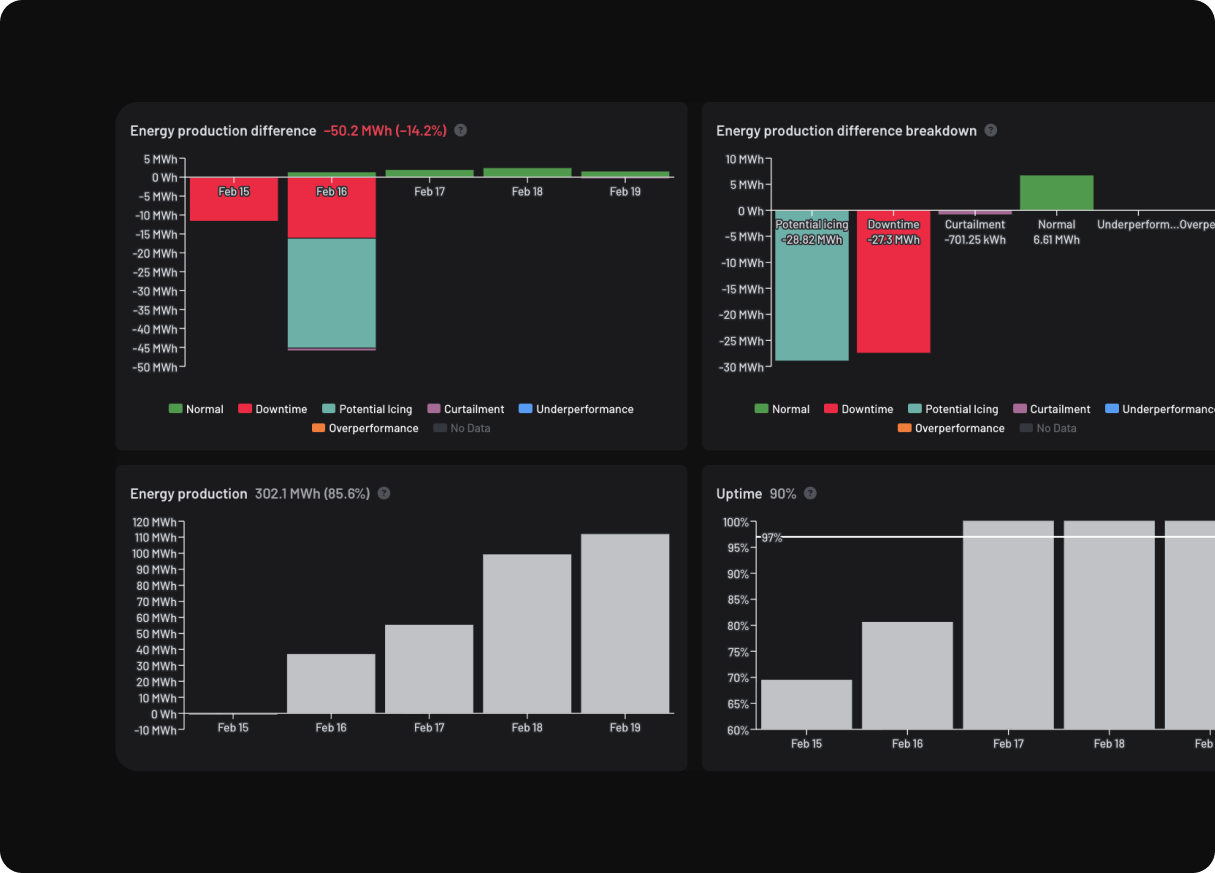


No, Canopy doesn't require special datasets or labeled input data. It leverages raw data from your existing sensors, eliminating the need for new sensor installations.
Typically, Canopy is up and running within two to three weeks, ensuring a swift and efficient deployment process and delivering value from day one.
Our models use historical sensor data to learn normal behaviour. In most cases, one year of historical data is enough to make very accurate predictions on the health and performance of your machines.
Yes! More and more customers have voiced the request to interact with our normality models and detections via API. Get in touch with our team if this is also of interest to your organisation.
Yes! Canopy's machine agnostic architecture allows it to work with a variety of machines. Our models learn unsupervised, which enables them to harness raw SCADA data, ensuring compatibility with different machine types and operational environments.
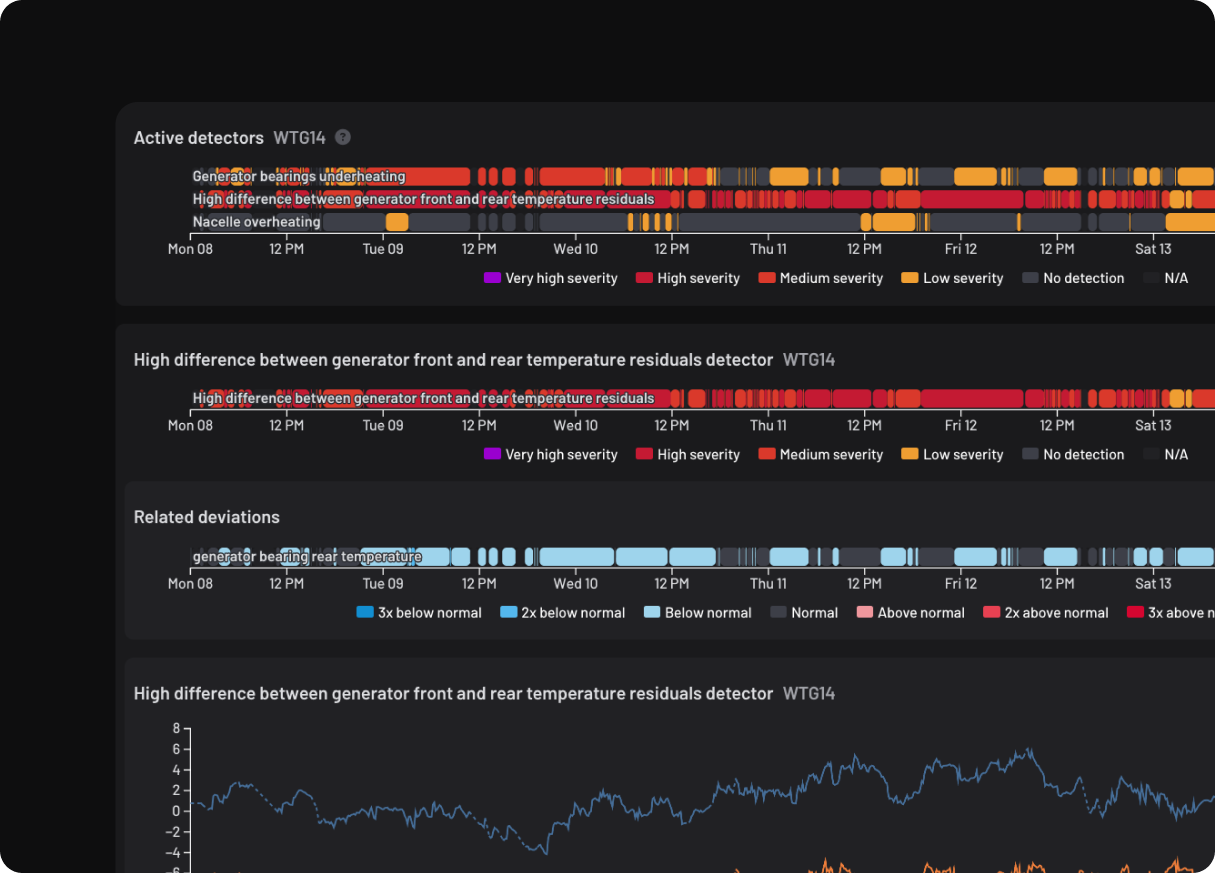
.png)

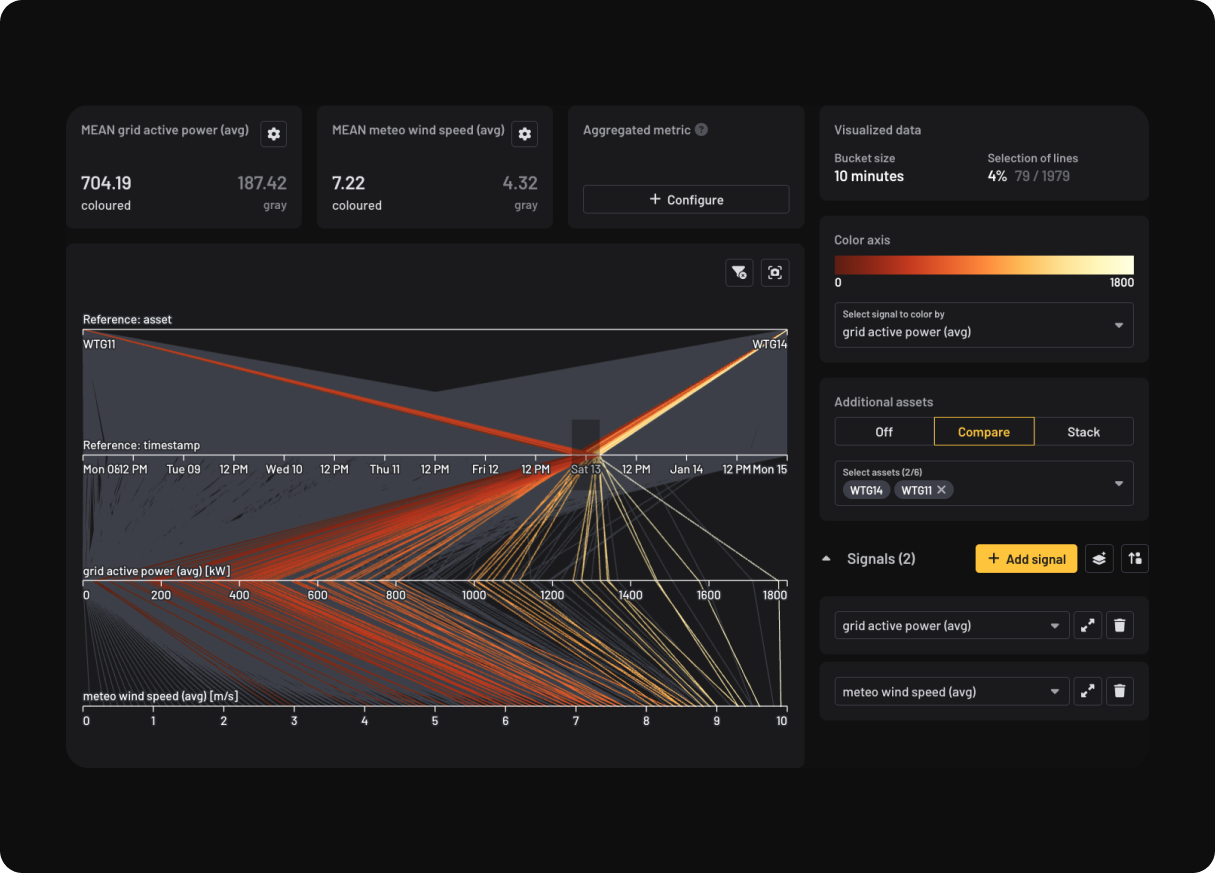
.png)





